Six-Sigma Analysis of Digital Standard Cells
The classic golden method to achieve reliable characterization has been Monte Carlo through intensive SPICE simulations. However, considering that libraries usually include dozens of types of standard cells that will be derived for different foundries, for different nodes, and for different process flavors, characterization under numerous process/voltage/temperature corners (PVTs) is a huge simulation burden that can take months, as shown in Figure 1.
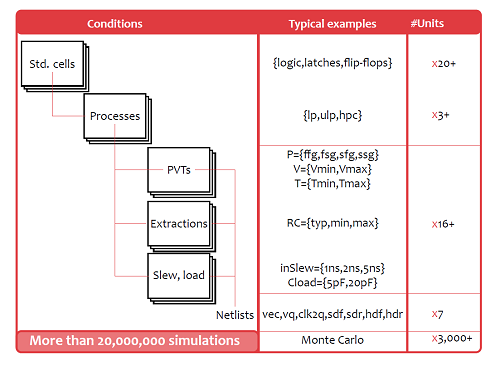
Figure1. Digital library characterization with variations: can involve millions of simulations.
High-sigma campaigns for digital library characterization require hundreds or thousands of CPUs and SPICE licenses across large and costly compute farms. The availability and cost of these resources to complete the necessary analysis is a serious difficulty for designers implementing such a flow. Monte Carlo characterization is accurate but has considerable disadvantages including being too time consuming to achieve enough precision and needing large computing resources. As a result, standard cell designers are looking for an effective and efficient solution for variation-aware digital library characterization. Ideally, changing only a single tool within their flow while preserving accuracy and precision would be desirable.
Depending on the standard cell property to be characterized, measurements of interest are presented in specific formats as shown in Table 2:
- Vector check, scan test, pass/fail to assure functionality and truth tables
- Logic output voltage values to assure functionality, check expected output level, check for stability, estimate margins
- Timings such as propagation delays, setup/hold times, constraint timings to estimate performance values
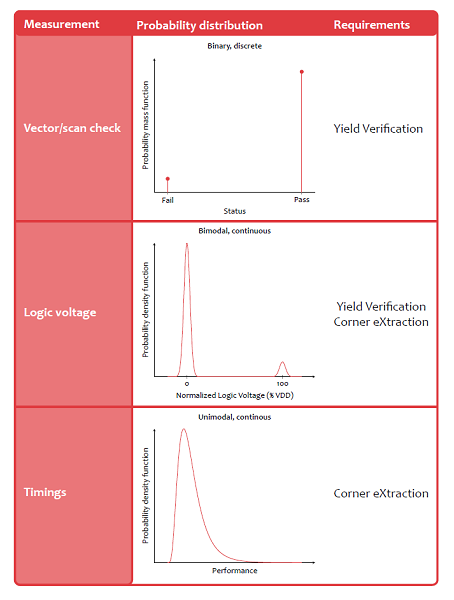
Figure 2. Typical probability distribuitons for corner and yield measurements.
Analyses to be performed with such targets are Yield Verification (YV) and Corner value extraction (CX). For advanced nodes and low power technologies, with their inherent process variations, Gaussian distributions no longer hold and, thus, analysis cannot rely on only a few Monte Carlo simulations.
Depending on the final SOC/ASIC application for the digital library, the requirements for variation-aware analysis might range from low to high-sigma. Attempting this with brute force Monte Carlo would require from 3,000 to more than 15,000,000,000 simulations per corner. For library development this can be unfeasible in practice. Statistical boosters for YV and CX that maintain accuracy and precision are required.
VarMan utilizes sampling strategies from recent machine learning advances to reduce the number of simulations necessary while maintaining accuracy and precision. Using SPICE iterations, VarMan explores process configurations that trigger extremes or failures to adjust its sampling strategy. As a result, VarMan does not rely on worst case distance or on model-based Monte Carlo ordering. This means that computations are very fast, and run-time is primarily dominated by meaningful SPICE simulations.
VarMan derives its estimates using dedicated statistical algorithms that are specific to the analysis bring performed. Typical simulation budgets for each of these VarMan algorithms are suitable for library applications, as three-sigma analysis can be achieved by simulating less than 1,000 samples per netlist, and six-sigma analysis using less than 20,000 simulations per netlist. Therefore, overall library characterization is feasible and can be realistically accomplished in weeks instead of months.
With VarMan, the full library characterization can be configured via a simple spreadsheet.
Six-Sigma Yield Verification
Given hundreds of truth-table checks or logic output voltages using 16nm and 7nm technologies, Var- Man agrees with large scale Monte Carlo simulations within time constraints. Accomplishing this within 15,000 simulations makes high-sigma characterization affordable where otherwise billions of Monte Carlo simulations would have been required.
Six-Sigma Corner Extraction
For hundreds of logic output voltages or delays using 16nm and 7nm technologies, VarMan provides corner values within percent relative deviation compared to large scale Monte Carlo simulations within the time constraints. Doing so with less than 20,000 simulations, high-sigma characterization becomes affordable where billions of Monte Carlo simulations would have been otherwise required.
With industrial successes like these, VarMan for library characterization has the strong potential to replace legacy Monte Carlo simulations, speeding up low-sigma and enabling affordable high-sigma with an emphasis on accuracy and precision.
In addition to VarMan for variation-aware characterization of digital libraries, Silvaco provides all the elements of a complete flow for standard cell designers. Cello and Viola products automate library creation and analysis, SmartSpice delivers high performance and accuracy for circuit simulations, Jivaro reduces parasitic elements to minimize their impact on simulation while preserving accuracy.
VarMan for library characterization is a game changing tool for standard cell designers. Silvaco is providing the necessary solutions to create high-quality nanometer digital libraries.
Click here to learn more about VarMan.

